Best script and info on SQL waits – http://www.sqlskills.com/blogs/paul/wait-statistics-or-please-tell-me-where-it-hurts/
Category: performance
Enable Enterprise Library Cache Performance Counters
These instructions are to enable the cache counters on a server where you have deployed code, and not installed Enterprise Library explicitly. This works for 4.1, but did not work with 3.0 a few years ago.
- Run InstallUtil against the Common and Caching dlls
- %WINDIR%Microsoft.NETFrameworkv2.0.50727InstallUtil Microsoft.Practices.EnterpriseLibrary.Common.dll
- %WINDIR%Microsoft.NETFrameworkv2.0.50727InstallUtil Microsoft.Practices.EnterpriseLibrary.Caching.dll
- Update the web.config to include the following items:
- <configSections><section name=”instrumentationConfiguration” type=”Microsoft.Practices.EnterpriseLibrary.Common.Instrumentation.Configuration.InstrumentationConfigurationSection, Microsoft.Practices.EnterpriseLibrary.Common, Version=4.1.0.0, Culture=neutral, PublicKeyToken=31bf3856ad364e35″ /></configSections>
- <instrumentationConfiguration performanceCountersEnabled=”true” eventLoggingEnabled=”false” wmiEnabled=”false” applicationInstanceName=”” />
- Counters should show up on the server as Enterprise Library Cache Performance Counters
- Run InstallUtil against the Common and Caching dlls
SharePoint 2010 Synthetic File Data
Still trying to work through creating synthetic data for an out-of-the-box SharePoint performance test. To create the data, create a new site collection (so it doesn’t interfere with anything else and is easy to clean up), and uploads all the test data. The biggest downside right now is that the data is created and then uploaded, which requires enough disk space to make the data. Not a huge issue for me, but possibly for you.
General idea came from a few places for the upload, and locally for the file creation.
#USER Defined Variables #Specify the extension type of files you want uploaded $strDocTypes = @(".docx",".xlsx", ".pptx", ".pdf") #The max amount of data generated in MB $maxSize = 50 #The max size one file could be in MB $maxFileSize = 10 #Intermediate folder where the test data is placed $fileSource = "F:TestData" #New Content Database (for easy removal) $dbName = "Portal_ContentDB2" #New Site collection template $template = "SPSPORTAL#0" #Account owner $siteOwner = "TESTAdministrator" #Web Application address $webApp = "https://portal" #Site Collection Address $siteCollection = "/sites/1" # DO not edit anything beyond this line #Create all the test data using FSUTIL $rand = New-Object system.random do { $guid = [guid]::NewGuid() $guid = $guid.ToString() $fileName = $guid+$strDocTypes[$rand.next(0,$strDocTypes.length)] $rand1 = $rand.nextdouble() $rand2 = $rand.nextdouble() $rand3 = $rand.nextdouble() [int]$fileSize = 1048576*$rand1*$rand2*$rand3*$maxFileSize FSUTIL FILE CREATENEW $fileName $fileSize $fileTotalBytes = $fileTotalBytes + $fileSize $fileTotal = $fileTotalBytes/1024/1024 } #Data generation keeps going until the amount of data is > $maxSize while ($fileTotal -le $maxSize) #Creation of the new content database and site collection $siteCollectionURL = $webApp + $siteCollection New-SPContentDatabase $dbName -WebApplication $webApp New-SPSite -url $siteCollectionURL -OwnerAlias $siteOwner -Name "Test Doc Library" -Template $template -ContentDatabase $dbName #uploading of all the generated data into the $siteCollectionURL/Documents folder $spWeb = Get-SPWeb -Identity $siteCollectionURL $listTemplate = [Microsoft.SharePoint.SPListTemplateType]::DocumentLibrary $spFolder = $spWeb.GetFolder("Documents") $spFileCollection = $spFolder.Files Get-ChildItem $fileSource | ForEach { $spFileCollection.Add("Documents/$($_.Name)",$_.OpenRead(),$true) }SharePoint 2010 Load Testing Kit
Was looking for ways to generate synthetic test data for a SharePoint out-of-the-box install today, and ran into the SharePoint 2010 Load Testing Kit. While it doesn’t help me in this stage of the project, I could see it being useful later or on other projects.
There appears to be a lot of dependencies though:
- Migration from 2007 to 2010
- As it collects info from your log files, you’ll need to have everything migrated for the scripts to work
- Data
- Apps
- Site Collections
- Etc.
Could be hot though!
Net.TCP, IIS7, and Classic AppPools
With the application that I’m helping “make fast” one of the optimizations identified by an architect was to use net.pipe or net.tcp on the application tier. This was because the services on that tier call into each other, and waste a lot of time doing all the encapsulation that comes with wsHttpBinding.
We had tried to first use net.pipe because it is incredibly fast and it is all local. However, because of how they do security here, it didn’t work. Next up, net.tcp.
Overall, it wasn’t that difficult to setup the services with dual bindings (wsHttpBinding for calls from other servers and net.tcp for calls originating from the same server). Granted, there were a lot of changes, and since all the configs are manually done here, was very error-prone. I will be glad not to do any detailed configurations for a while.
Anyways, we did our testing of the build that incorporated it through 3 different environments, and over the weekend it went into Production. Of course, that is when the issues started.
Bright and early Monday morning, users were presented with a nice 500 error after they logged into the application. On the App tier servers we were getting the following error in the Application event log with every request to the services:
Log Name: Application Source: ASP.NET 4.0.30319.0 Event ID: 1088 Task Category: None Level: Error Keywords: Classic User: N/A Description: Failed to execute request because the App-Domain could not be created. Error: 0x8000ffff Catastrophic failure
Well, since it mentioned the App Domain, we ran an IISReset and all was well. I didn’t think too much into it at the time and only did some cursory searching as it was the first time we saw it. However, today it happened again.
Our app is consistently used between 7AM and about 7PM, but during the night it isn’t used at all. This is when the appPool is scheduled to be recycled (3AM). It had appeared as if the recycle was what was killing us, as only the App Domain is recycled and not the complete worker process.
Immediately we had the guys here remove the nightly recycle and change it to a full IISReset. At least that way we had a workaround until we could determine the actual root cause, come up with a fix, and test said fix. However, it didn’t take long to determine the actual root cause…
One of the interesting things about this issue, was after it started happening in Production, a few of the other environments started exhibiting similar symptoms: Prod-Like and a smaller, sandbox environment. Mind you, neither of these environments had these issues during testing.
So, I took some time to dive in and actually figure out the problem. At first I thought it was because there were some metabase misconfigurations in these environments. I wouldn’t say that all of these environments were pristine, nor consistent between each other. I found a few things, but nothing really stood out…until…
While I was doing diffs against the various applicationHost.config files, NotePad++ told me it had been edited and needed to be refreshed (them removing the appPool recycles). However, as soon as this happened the 500 errors started. It didn’t help they did both machines at the same time which took down the whole application, but that’s another story.
This led me to believe that it wasn’t something within the configuration, but it also showed me how to reproduce it, at least part way. The part that I was missing was that I had to first hit the website to invoke the services and then change the configs causing an app domain recycle.
Then I attempted to connect to the worker process with windbg to see what it was doing. However, that was a complete failure as nothing actually happened to the process. No exceptions being thrown, no threads stuck, etc. It appeared to just sit there.
A bit of searching later led me to an article that had the exact same issues we were having, and that changing from a Classic to Integrated appPool fixed it. However, it didn’t mention why. Of course I tried it and it worked. To appease the customer’s inquiries I knew I needed to find out why though.
I still don’t have a great solution, but apparently net.tcp and WAS activation has to be done in Integrated mode. If it isn’t, you get the 500 error. But ours works fine until the app domain is recycled. Well, according to SantoshOnline, “if you are using netTcpBinding along with wsHttpBinding on IIS7 with application pool running in Classic Mode, you may notice the ‘Server Application Unavailable’ errors. This happens if the first request to the application pool is served for a request coming over netTcpBinding. However if the first request for the application pool comes for an http resource served by .net framework, you will not notice this issue.”
That would’ve been nice to know from Microsoft’s article on it, or at least a few more details. I remember reading an article about the differences between Integrated and Classic, but I sure don’t remember anything specific to this.
Anyways, hope this helps someone who runs into the same issue…
Windows 2008 Performance Alerts
This may seem silly to some of you, but I am still getting used to Windows 2008. Sadly, I don’t spend as much time actually administering servers as I used to (silly management), so it usually takes me a bit longer to make my way around 2008 than 2003. I like to think they made everything more complex, but for some reason I’m sure I’ll get booed about that.
Anyways, this morning I was attempting to setup some performance alerts on some servers we’re having issues with. Basically I wanted to have it email us when it reached a certain threshold. No big deal, thinking I had this, I created the email app, created a performance counter, and then manually added it in.
Needless to say that didn’t work. It took me awhile to figure out why too as my little email utility worked fine. So I began a new search in order to find out how stupid I was being.
Turns out, quite a lot of stupid. Instead of using the utility, you can now use scheduled task items…which includes an email action! I basically used the instructions over at Sam Martin’s blog, which, I may add, he posted about in April of this year. I’m not the only n00b. Plus, who doesn’t have an enterprise system that deals with this sort of stuff already (at least at the types of clients I work with)?
Perfmon
- Open up perfmon
- Create a new User Defined Data Collector Set
- Choose to create manually after naming
- Select Performance Counter Alert
- Add in the performance counter you care about (mine was requests executing in asp.net apps 4.0)
- Choose the user to run it as
- Edit the Data Collector in the Data collector set
- Change the sample interval to whatever works for you (I set mine to 60s so we can be on top of issues prior to the users)
- Under Alert task, give it a name (e.g. EmailAlert) and give it a task argument (you can combine them to form a sentence like “the value at {date} was {value}”
- Start the Data Collector Set
Schedule Tasks- Open up scheduled tasks
- Create a task, not a basic task
- Name it the exact same name you did in step 9 above (i.e. EmailAlert)
- Check “user is logged in or not” so that it runs all the time
- Create a new email action under the Action tab
- Enter all the info for from, to, subject, etc. To send to multiple people, comma separate the addresses.
- For the body, type whatever you want, and then $(Arg0) will pass the task argument you made in step 9 above.
- Enter the SMTP server.
Done!
Since the performance counter was set to an application pool, whenever that pool disappears (IISReset, idle timeout, etc.) the counter stops.
Currently Reading (could take awhile): [amazon_image id=”B000QCS8TW” link=”true” target=”_blank” size=”medium” ]A Game of Thrones: A Song of Ice and Fire: Book One[/amazon_image]
More Visual Studio 2010 Performance Testing "Fun"
This is a continuation of my previous post on the half-baked core features of load testing in Visual Studio 2010. We had been progressing fairly well, but with some of the new fixes that have gone into the application, we have reached new issues.
I would like to preface this with our application is by no means great. In fact, it is pretty janky and does a lot of incredibly stupid things. Having a 1.5MB viewstate (or larger) is an issue, and I get that. However, the way that VS handles it is plain unacceptable.
With that said, I’m sure you can imagine where this is going. When running an individual webtest each request cannot be larger than 1.5MB. This took a bit of time to figure out as many of our tests were simply failing. The best part of this is that we have a VIEWSTATE extract parameter (see #1 on the previous post), and the error we always get is that the VIEWSTATE cannot be extracted. Strange, I see it in the response window when I run the webtest. Oh, wait, does that say Response (Truncated)? Oh right, because my response is over 1.5MB.

Oh, and that’s not just truncated for viewing, that’s truncated in memory. Needless to say this has caused a large amount of issues for us. Thankfully, VS 2010 is nice and you can create plugins to get around this (see below). The downside is that VS has obviously not been built to run webtests with our complexity, and definitely not bypassing the 1.5MB sized response.
public override void PreWebTest(object sender, PreWebTestEventArgs e) { e.WebTest.ResponseBodyCaptureLimit = 15000000; e.WebTest.StopOnError = true; base.PreWebTest(sender, e); }If you use this plugin, be prepared for a lot of painful hours in VS. I am running this on a laptop with 4GB of RAM, and prior to the webtest running devenv.exe is using ~300MB of RAM. However, during the test, that balloons to 2.5GB and pegs one of my cores at 100% utilization as it attempts to parse all the data. Fun!
The max amount of data we could have in the test context is 30MB. Granted, as mentioned earlier, this is a lot of text. However, I fail to see how it accounts for almost 100x that amount in RAM.
Thankfully, in a load test scenario all that data isn’t parsed out to be viewed and you don’t have any of these issues. You just need to create perfect scripts that you don’t ever need to update. Good luck with that!
Oh and as an update, for #3 in my previous post, I created a bug for it, but haven’t heard anything back. Needless to say, we are still having the issue.
And I realize that we’ve had a lot of issues with VS 2010, and I get angry about it. However, I want to re-iterate that no testing platforms are good.
"Fun" with Visual Studio 2010 Performance Testing
As I am sure you can tell from the title of this post, we have been having nothing but issues using Visual Studio 2010 on the current solution we are performance testing. While this is going to be a bitch session, with possible solutions and workarounds we have found, these issues are in no way limited to only Visual Studio.
As one of my coworkers said, “I’m learning that every load testing solution is shit.” Sadly, the more you work with them, and the more complex the solution, the quicker you come to this realization. This becomes even more clear as we are expected to bounce around between different performance testing solutions, being pseudo-masters on a smattering of them. While it is expensive, outsourcing to someone like Keynote may possibly be the best answer (I have used and work with these guys before, and they are great).
Without further ado, let me breakdown the issues we’ve been having so far. I really, really, really hope that this list doesn’t continue to grow as we are already running out of time.
- Scripting. We had a bear of a time with scripting our specific website. No matter what we did, there was no way to get it to actually work by scripting it with Visual Studio. The website in general is fairly basic, but is loaded up with a ton of Telerik controls per page (don’t even get me started!). Each stage of our workflow has a bunch of these controls and then a final submit button that moves it into the next stage. Scripting with VS always failed on the subsequent AJAX postbacks because it was not correctly parameterizing the values (wasn’t extracting some). However, this only happened when we scripted all the way to through the final submit. If we scripted, but did not include the final submit button, the script worked correctly and did not have any of the errors. Since the Telerik controls have so many forms in the post fixing the parameterization issue by hand would’ve taken hours per page (each workflow has 7 pages and there are 17 workflows). And we couldn’t figure out how to simply wire up the final submit to the working rest of the script. No matter what we did we’d always get errors on the final submit POST. The solution? Use Fiddler and save the sessions as a webtest. This has a lot of downsides, such as no parameterization at all and the scripts break pretty easily once any code changes. Fun.
- Load Testing Workflows with NTLM Authentication. The next issue we ran into was with wiring up the individual workflow pieces into one large workflow. The breakdown was that each part of the workflow needed to be handled by a different user, and the users would log in via NTLM. The most obvious way to do this was to have a webtest call another webtest. However, we weren’t able to get that to work. The next way was to use an ordered test, but that didn’t give us reports into individual page loads. The final way was to create a load scenario that runs scripts in a specific order, but that would require a lot of controllers among other things. In our desperation, I even created an MSDN question. The solution? We created a plugin that cleared the user’s cookies (even though it should’ve been running as a unique user 100% of the time), and also accessed a server redirect page to force the authentication request. Thankfully we didn’t go down the road of rolling our own queuing system as that would’ve been painful.
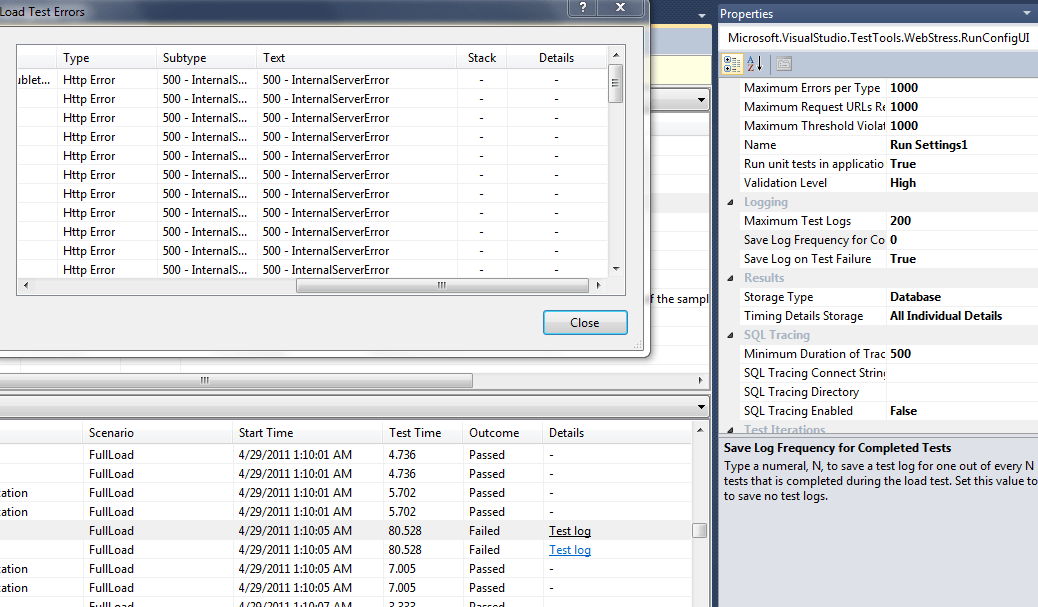
- Lack of Test Logs after a Run. Now that we were actually able to run tests, we were having all sorts of issues with results. Sadly, we weren’t able to actually view the results because VS wasn’t saving them.
 Again, in desperation I created another MSDN question. With VS2010, you are supposed to be able to capture all the results of failed tests, and the select “Test Log” to see what the results are. Unfortunately, when we run tests it sometimes shows up, and sometimes not. However, for anything longer than a 15 minute run, ours were 60 mins, we never received any results. We also get links to the “Test Log”, but they don’t do anything when you click. The solution? Yeah, as of now we don’t have one other than running two controllers: one running the full load and another one running individual tests to hopefully see a similar error message.
Again, in desperation I created another MSDN question. With VS2010, you are supposed to be able to capture all the results of failed tests, and the select “Test Log” to see what the results are. Unfortunately, when we run tests it sometimes shows up, and sometimes not. However, for anything longer than a 15 minute run, ours were 60 mins, we never received any results. We also get links to the “Test Log”, but they don’t do anything when you click. The solution? Yeah, as of now we don’t have one other than running two controllers: one running the full load and another one running individual tests to hopefully see a similar error message.
I can only hope that there are no other issues. Hope, hope, hope!
SQL Dashboard 2005 for SQL 2008
- Install the Dashboard by running the msi, which will attempt to install to a default location of Program FilesMicrosoft SQL Server90ToolsPerformanceDashboard. Save the files to the Program FilesMicrosoft SQL Server100ToolsPerformanceDashboard directory instead
- Replace performance_dashboard_main.rdl in the PerformanceDashboard folder with the updated version attached below
- Open Management Studio and connect to the server and run the SETUP.SQL script (once for each SQL instance you want to monitor) located below and in attachment
- From Object Explorer select the server, right mouse click and choose Reports – Custom Reports and browse to find the PERFORMANCE_DASHBOARD_MAIN.RDL file. This report is the only report intended to be directly loaded from SSMS; all other reports are accessed as a drill through off of the main report
IIS Log Analysis
Some good things to use when trying to do analysis on IIS logs:
- TXTCollector – This will make all your individual IIS log files into one large file.
- Log Parser – Write SQL queries against your IIS Log files
- Visual Log Parser – No command line (but sometimes a pain in the ass to install)!
- Log Parser Lizard – Visual Log Parser doesn’t want to install anymore, so a new tool it is!
- Log Parser Studio – Free from MS!
Some common Log Parser queries:
select cs-uri-stem as url, cs-uri-query, cs-method, count(cs-uri-stem) as pagecount, sum(time-taken) as total-processing-time, avg(time-taken) as average, Max(time-taken) as Maximum from <logfile> group by cs-uri-stem, cs-uri-query, cs-method order by average desc
select cs-uri-stem as url, cs-method, count(cs-uri-stem) as pagecount, sum(time-taken) as total-processing-time, avg(time-taken) as average from <logfile> where cs-uri-stem like '%.aspx' group by cs-uri-stem, cs-method order by pagecount desc
select top 500 cs-uri-stem as url, cs-uri-query, count(cs-uri-stem) as pagecount, sum(time-taken) as total-processing-time, avg(time-taken) as average from <logfile> where cs-uri-stem like '%.aspx' group by cs-uri-stem, cs-uri-query order by pagecount desc
select cs-uri-stem as url, cs-method, count(cs-uri-stem) as pagecount, sum(time-taken) as total-processing-time, avg(time-taken) as average, avg(sc-bytes), max(sc-bytes) from <logfile> where cs-uri-stem like '%.aspx' group by cs-uri-stem, cs-method order by pagecount desc
UpdateI’m just adding more queries I frequently use, and fixing the formatting.
select quantize(time-taken,5000) as 5seconds, count(cs-uri-stem) as hits, cs-uri-stem as url from <logfile> group by url, quantize(time-taken,5000) order by quantize(time-taken,5000)
select quantize(time,3600) as dayHour, count(cs-uri-stem) as hits, avg(time-taken) as averageTime, cs-uri-stem as url from <logfile> where url like '%.svc' group by url, dayHour order by dayHour
select TO_LOCALTIME(QUANTIZE(TO_TIMESTAMP(date, time), 3600)) AS dayHour, count(cs-uri-stem) as hits from <logfile> where cs-uri-stem like '%/page.aspx' group by dayHour order by dayHour Asc
{kind=link}